WWDC 2017 - What’s New in Foundation
视频: WWDC 2017 - Session 212 - What’s New in Foundation
原文: What’s New in Foundation
作者: kemchenj
新 API 概览
FileProviderAPI 的增强- 优化了查询剩余空间的 API
- 优化了
NSString的Range与Swift.String的Range的转化 - 从
NSXPCConnection剥离出NSProgress - iOS 新增温度感应通知的 API
Foundation 的优化
- NSArray,NSDictionary,NSSet 以及他们的 mutable 类型新增 Copy-On-Write 的行为。做这个最大的原因是为了更好地桥接到 Swift,当
NSArray从 Objective-C 的 API 返回时,你就会得到一个 Swift 的值类型Array,为了值语义,这些结构体会调用NSArray的copy去获取一个副本,如果刚好这个副本是一个 mutable 的类型,那对于性能影响可能会很大。现在我们可以通过 Copy-On-Write 去避免性能损耗,直到这个值实际被改变的时候才去进行 必要的操作。这样做让性能得到大幅提升。 - Data 的 API 内联化。Swift Foundation 里的
Data结构体,也做了很多的性能优化。很赞的一件事情是我们可以让 Data 的部分行为直接内联到你的 app 里,例如索引到 data 里的每一个 byte,这对于性能提升的作用也很大。 - 更快的日期计算,更低的内存占用。
- 提升了 NSNumber 桥街到 Swift 的性能。这对于提高 Property List 的编码解码性能来说很重要。更多信息,请查看 Efficient Interactions with Frameworks。
Key Paths 与 Key Value Observation
KeyPath 对于 Cocoa 的使用非常重要,因为它可以通过类型的结构,去获取到任意一个实例的相应属性,而且这种方式远比 Block 更加简单和紧凑。
而它还没有完全融入到 Swift 的语言本身里,所以去年我们在 Swift 3 里新增了类型安全的 keyPath,这可以让编译器在编译期去检查 keyPath 的正确性。
让我们来回顾一下之前的写法,首先我们有一个 Kid 类型,然后我们通过 keyPath 使用 KVC 去获取和修改 Kid 的名字。@objcMembers class Kid : NSObject {
dynamic var nickname : String = ""
dynamic var age : Double = 0.0
dynamic var bestFriend : Kid? = nil
dynamic var friends : [Kid] = []
}
let ben = Kid(nickname: "Benji", age: 5.5)
let kidsNameKeyPath = #keyPath(Kid.nickname)
let name = ben.valueForKeyPath(kidsNameKeyPath) // valueForKeyPath(_: String) -> Any
ben.setValue("Ben", forKeyPath: kidsNameKeyPath) // setValue(_: Any, forKeyPath: String)
kidsNameKeyPath 最终还是会编译成一个 String,它并没有携带任何类型信息,那这会导致什么结果:
- 我们需要 Objective-C 的 runtime 才能让这个字符串变得有意义,而 Swift 的原生类型就不支持这种做法。
- 由于 keyPath 没有携带类型信息,所以
valueForKeyPath(_: String) -> Any和setValue(_: Any, forKeyPath: String)就都做不到类型安全。
但这是 Swift,我们可以做得更好,那一个足够 Swifty 的 keyPath 应该是怎么样的:
- 可递归嵌套
- 类型安全
- 足够快
- 适用于所有 Swift 类型
- 所有平台都能够支持(不需要借助 Objective-C 的 runtime)
基础语法
最终的成果就是 Swift Evolution 的 SE-0161 Smart KeyPath 提案,声明的方式如下:

首先是反斜杠,以便 keyPath 与其它语法区分开来,接着是基本类型,再加一个点和属性名。
keyPath 支持递归声明,可以声明 property 的 property 的 property……\Kid.nickname.characters.count
optional chaining 也可以直接使用\Kid.bestFriend?.nickname
还可以直接使用 subscript\Kid.friends[0]
通过类型推导可以在书写时省略掉不必要的元素\Data.[.startIndex]
\.[.startIndex] // 与上面的表达式等价
这种 keyPath 为 Swift 所有类型提供了统一的语法格式:
通过 keyPath 读取数据的方式也很简单let age = ben[keyPath: \Kid.age]
使用 keyPath 去修改数据的语法也一样ben[keyPath: \Kid.nickname] = "Ben"
值类型的 KeyPath 使用
刚刚展示的都是引用类型的 keyPath 使用方法,那为了演示,我们首先定义一个 BirthdayParty 结构体。// 使用 Swift 4 的 KeyPaths
struct BirthdayParty {
let celebrant : Kid
var theme : String
var attending : [Kid]
}
let bensParty = BirthdayParty(celebrant: ben, theme: "Construction", attending: [])
let birthdayKid = bensParth[keyPath: \.celebrant]
bensParty[keyPath: \.theme] = "Pirate"
首先由于这里的 keyPath 很明显基础类型都是 bensParty,所以可以省略不写,这里我们看到的只是结果,那实际上到底发生了什么呢?let nicknameKeyPath = \Kid.nickname
上面 keyPath 的表达式实际上会产生一个类型实例,那这个实例是什么类型呢?从 Xcode 里直接查看的话,我们可以看到类似于下图的内容:
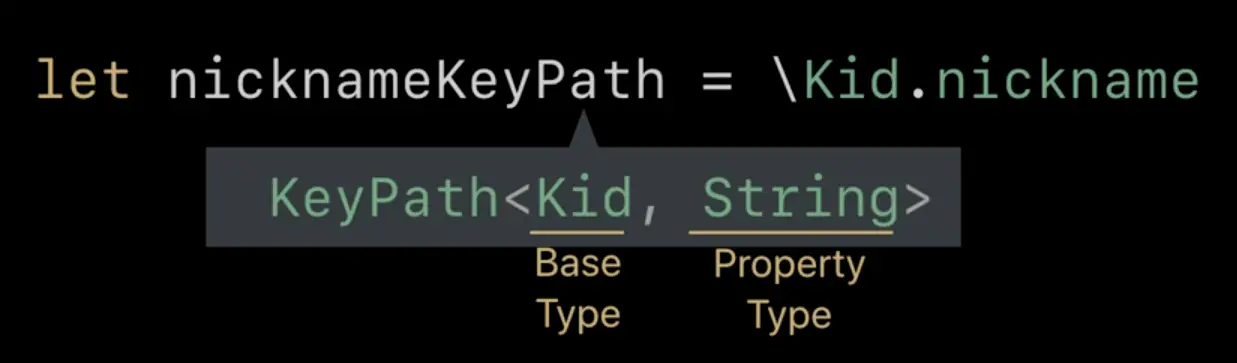
KeyPath 类型的第一个泛型是这个 KeyPath 指向的基础类型,而第二个是 KeyPath 最终指向的属性的类型。
同时 KeyPath 还支持拼接组合:let particalpantPath = \BirthdayParty.attending
let kidAgeKeyPath = \Kid.age
let allKidsAgeKeyPath = participantPath.appending(kidAgeKeyPath)
let allKidsAge = miasBirthday[keyPath: allKidsAgeKeyPath]
当我们需要把 KeyPath 保存到数组里面的时候,如果它的基本类型都是一样的,但最终指向的属性类型不同的话,就可以使用 KeyPath 的父类 PartialKeyPath 去做一个统一的容器:let titles = ["Theme", "Attending", "Birthday Kid"]
// 编译器自动推导为 [PartialKeyPath<BirthdayParty>]
let partyPaths = [\BirthdayParty.theme, \BirthdayParty.attending, \BirthdayParty.celebrant]
for (title, partyPath) in zip(titles, partyPaths) {
let partyValue = miasParty[keyPath: partyPath]
print("\(title): \(partyValue)\n")
}
如果需要通过 KeyPath 去修改一个值类型的变量的时候,我们需要使用的类型是 WritableKeyPath。let kidNicknameKeyPath : WritableKeyPath<Kid, String> = \Kid.nickname
ben[keyPath: kidNicknameKeyPath] = "Ben"
但我们使用 WritaleKeyPath 的时候,可能会出现这样的情况:@objcMembers class Kid : NSObject {
dynamic var age : Double = 0.0
...}
struct BirthdayParty {
var celebrant : Kid
...
}
extension BirthdayParty {
func blowCandles(ageKeyPath: WritableKeyPath<BirthdayParty, Double>){
let age = self[keyPath: ageKeyPath]
self[keyPath: ageKeyPath] = age + 1 // 编译不通过
}
}
bensParty.blowCandles(ageKeyPath: \.celebrant.age)
这里通过 WritableKeyPath 去修改 bensParty 的 kid 的属性,而 kid 是引用类型,这个修改实际上并不会改变 bensParty 的值。
当使用 WritableKeyPath 的基础类型为值类型的时候,通过这个 keyPath 去修改值,会被认为是修改了。
在这里解决方法很简单,改为使用 ReferenceWritableKeyPath 这个类型就可以正确地表达这样的含义了。func blowCandles(ageKeyPath: ReferenceWritableKeyPath<BirthdayParty, Double>){ ... }
总结一下两种 keyPath 的区别
- WritableKeyPath。基于这种 keyPath 的修改意味着值的修改
- ReferenceWritableKeyPath。基于这种 keyPath 的修改意味着引用的修改
keyPath 会捕获值,而不像 block 那样
var index = 0 |
keyPath 并不会捕获 index 的引用,而是直接捕获了 index 的值,所以 keyPath 不会随着 index 的修改而修改。
KVO 的语法得到了简化
observe 方法返回的是一个 NSKeyValueObservation,block 里参数分别是被观察的对象,便于我们操作的时候不容易产生引用循环,以及一个 NSKeyValueObservedChange 对象。let observation = ben.observe(\.age) { (ben, chagne) in
...
}
NSKeyValueObservation 可以手动调用 invalidate 方法注销掉 KVO,它在被销毁的时候也会自动去调用 invalidate,正常情况下找个生命周期合适的对象保存好它就行了(例如 ViewController)。
然后 NSKeyValueObservedChange 封装了改动的信息,包括新值旧值,修改类型,不需要像以前那样需要手动从字典里取出来了。public struct NSKeyValueObservedChange<Value> {
// change 的类型
public typealias Kind = NSKeyValueChange
public let kind: NSKeyValueObservedChange.Kind
// 新值和旧值
public let newValue: Value?
public let oldValue: Value?
public let indexes: IndexSet?
// `isPrior` 如果是 true 的话,observation 会在实际修改之前触发。
// `isPrior` 的值由 `observe` 方法传入的参数决定
public let isPrior: Bool
}
Encoding and Decoding
编码解码,其实就是格式化数据与 Swift 的数据结构相互转化的过程,而 Swift 的强类型特性与结构松散的格式化数据显得格格不入,特别是 JSON,Swift 团队认为只有让语言本身去处理这个问题才是最合适的,让编译器,标准库帮助一起完成这个过程。
现在 JSON 解析的操作非常简单,只要让我们需要解析的类型遵循 Codable 就可以了:let jsonData = """{ "name" : "Monalisa Octocat", "email" : "support@github.com", "date" : "2011-04-14T16:00:49Z"}""".data(using: .utf8)!
// 让我们需要解析的类型遵循 Codable 协议struct Author : Codable { let name : String let email : String let date : Date}
let decoder = JSONDecoder() // 创建一个解码器decoder.dateDecodingStrategy = .iso8601 // 设置一下日期编码的形式let author = try decoder.decode(Author.self, from: jsonData) // 完成
Codable
Codable 实际上包含了两个协议,Encodable 和 Decodable,实现如下:typealias Codable = Encodable & Decodable
public protocol Encodable {
func encode(to encoder: Encoder) throws
}
public protocol Decodable {
init(from decoder: Decoder) throws
}
Codable 包含了两个协议 Encodable 和 Decodable。
Coding 相关的这些 protocols 都借助了 protocol extension,让我们可以有自定义的实现,也可以直接使用默认的实现。struct Commit : Codable {
struct Author : Codable { ... }
let url : URL
let message : String
let author : String
let comment_count : Int
//Encodable ▲
public func encode(to encoder: Encoder) throws { ... } |
| 编译器生成
// Decodable |
init(from decoder: Decoder) throws throws { ... } ▼
}
只要让我们自定义的类型遵循 Codable,编译器就会自动为我们插入 encode(to:) throws 和 init(from:) throws 的实现。这两个方法我们目前都不需要自定义,那么直接忽略掉就行了,但是我们发现 comment_count 并不符合 Swift 的命名规则,这个时候就需要来关注一下编译器为我们自动插入的另一段内容,一个 private 的 CodingKeys 枚举,遵循 CodingKey 协议(稍后我们会更深入地探讨这个协议)。struct Commit : Codable {
struct Author : Codable { ... }
let url : URL
let message : String
let author : String
let comment_count : Int
private enum CodingKeys: String, CodingKey { ▲
case url |
case message | 编译器生成
case author |
case comment_count |
} ▼
}
CodingKeys 里包含了四个 case,跟我们声明的四个属性名字一样,当我们需要自定义的时候,只需要修改相应的 case 即可。struct Commit : Codable {
struct Author : Codable { ... }
let url : URL
let message : String
let author : String
let commentCount : Int
private enum CodingKeys : String, CodingKey {
case url
case message
case author
case commentCount = "comment_count"
}
}
把属性名和 case 名都改为 commentCount,然后把 commentCount 的 rawValue 改为数据里对应的 key 就可以了。
如果类型的属性全部都遵循 Codable 的话,我们只要让自己的类型遵循 Codable,其它的交给编译器就可以了,而且标准库里面绝大部分基本数据类型现在都已经实现了 Codable 协议,所以基本上我们一句代码就能完成 JSON 解析的功能了。
实战例子
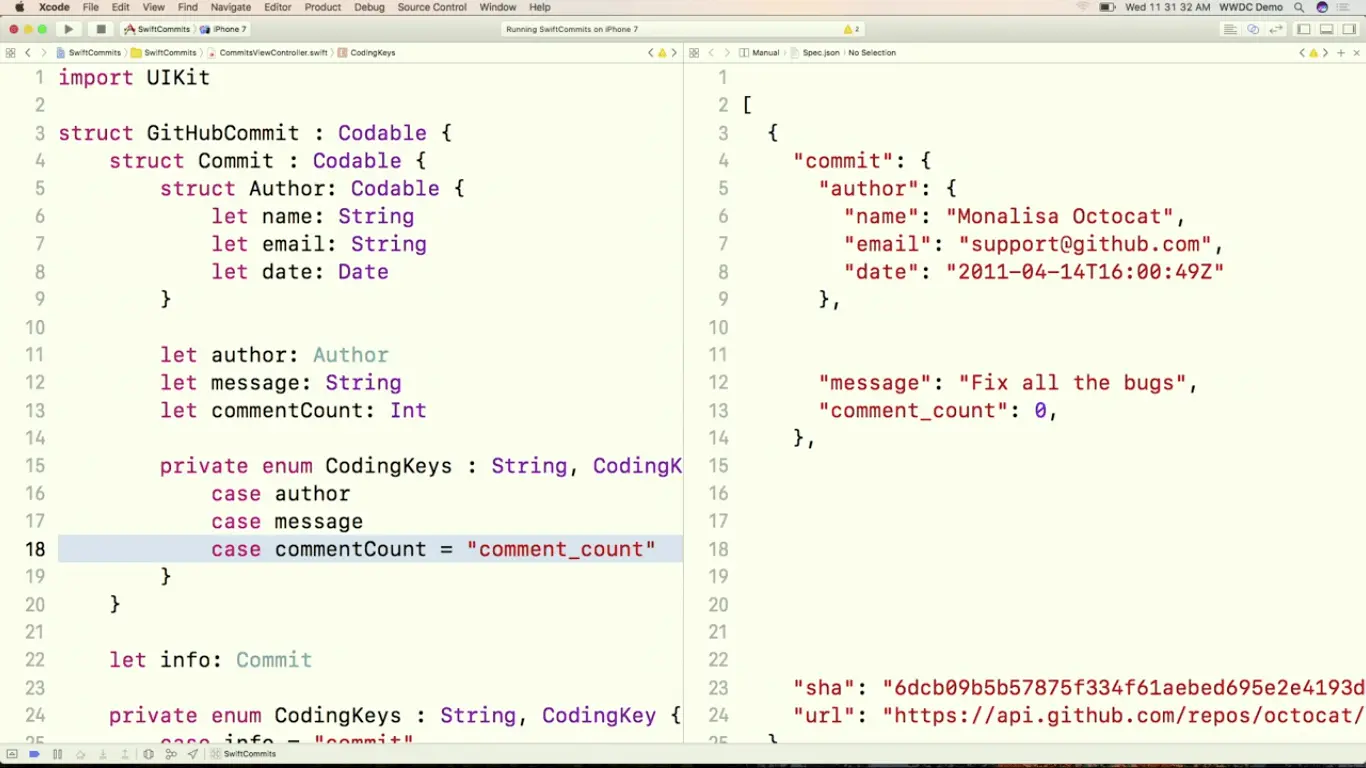
这里我们来看一个 App,这个 App 让我们能够查看 Swift repo 的提交。这里的 Commit 比起之前复杂了一点,右边是服务器返回的的 JSON 数据。
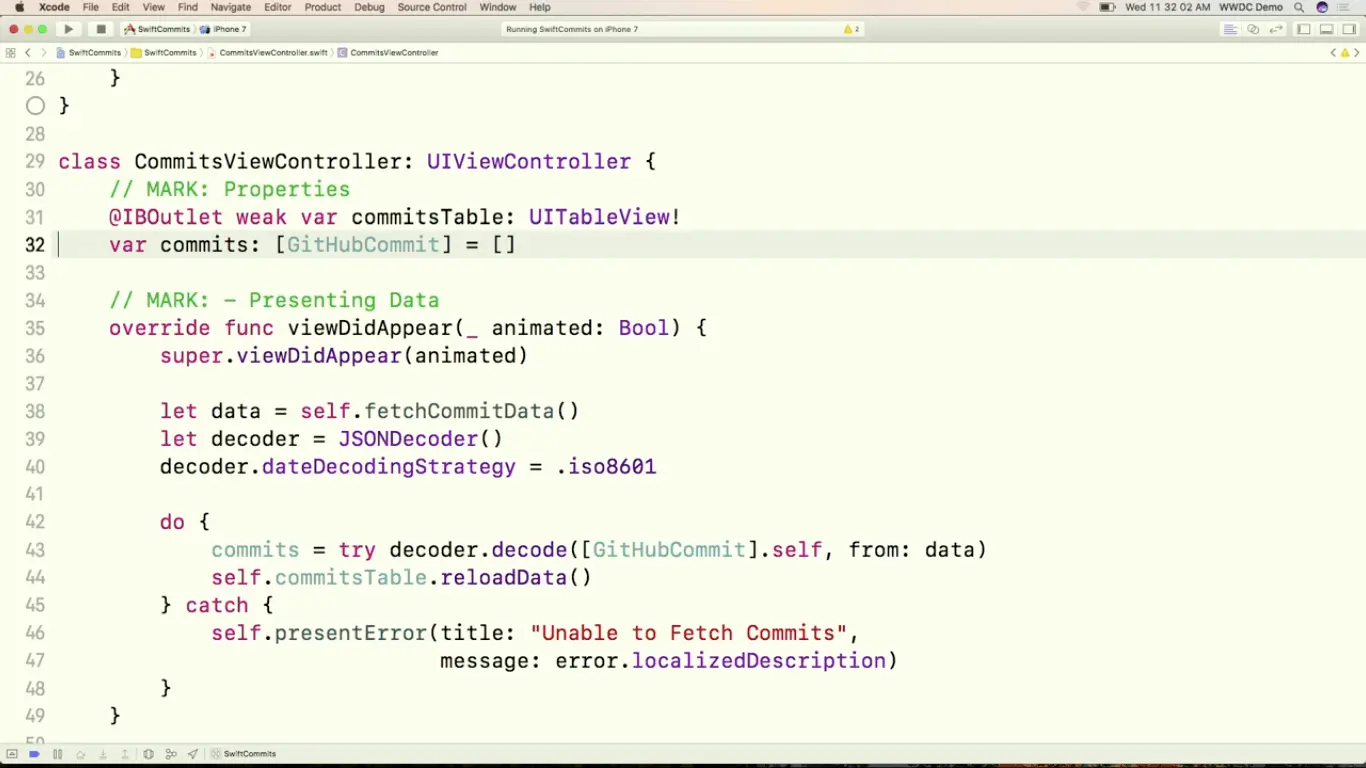
App 的逻辑很简单,分成下面几步
- 获取 Commit 的数据
- 创建一个 Decoder
- 设置 decoder 的日期解码格式
- 由于 decode 方法会抛出错误,所以我们需要用一个 do catch 来包住它
- 如果解码成功,我们就把数据填充到 commits 数组里,刷新 UI 数据
- 如果解码出错,我们就把错误原因呈现出来
界面里特意留了一个让 SHA 值显示的空位,那先让我们把 Commit 的 SHA 值显示出来吧
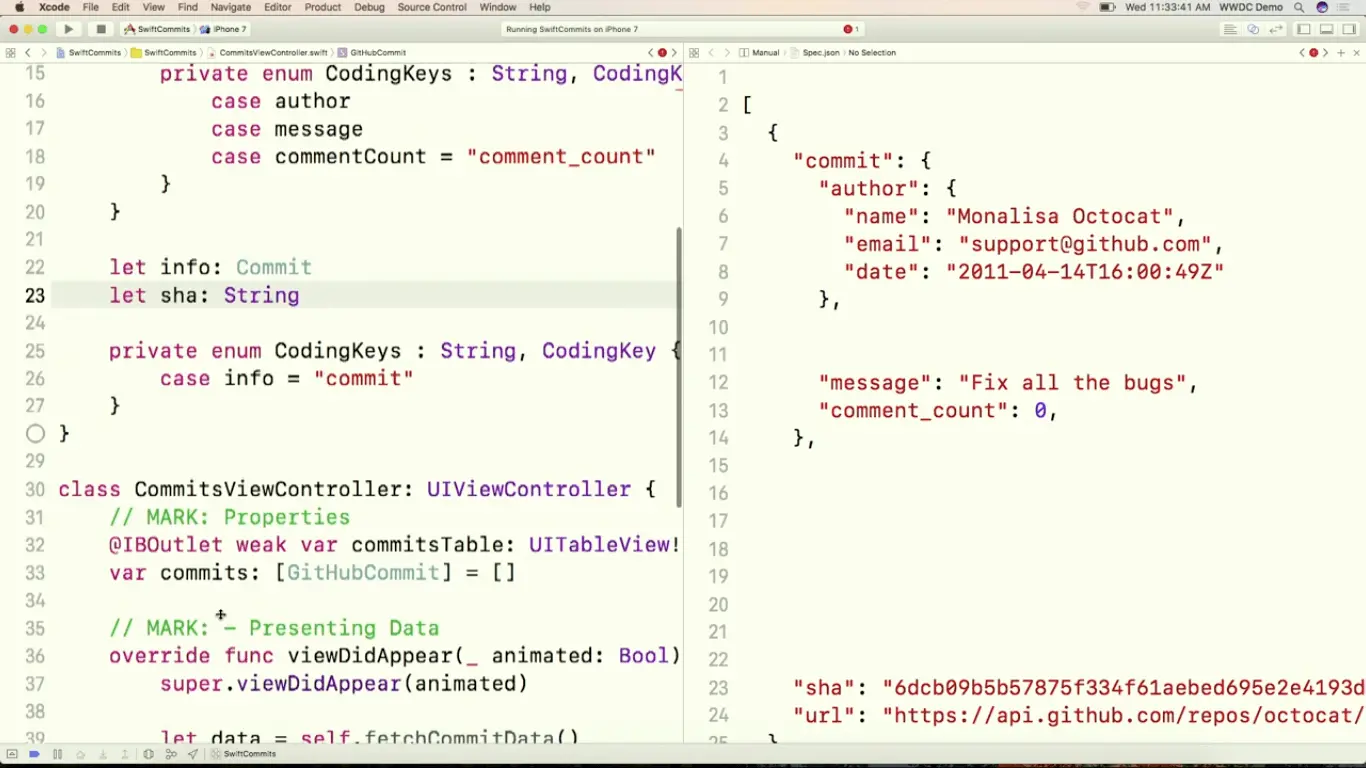
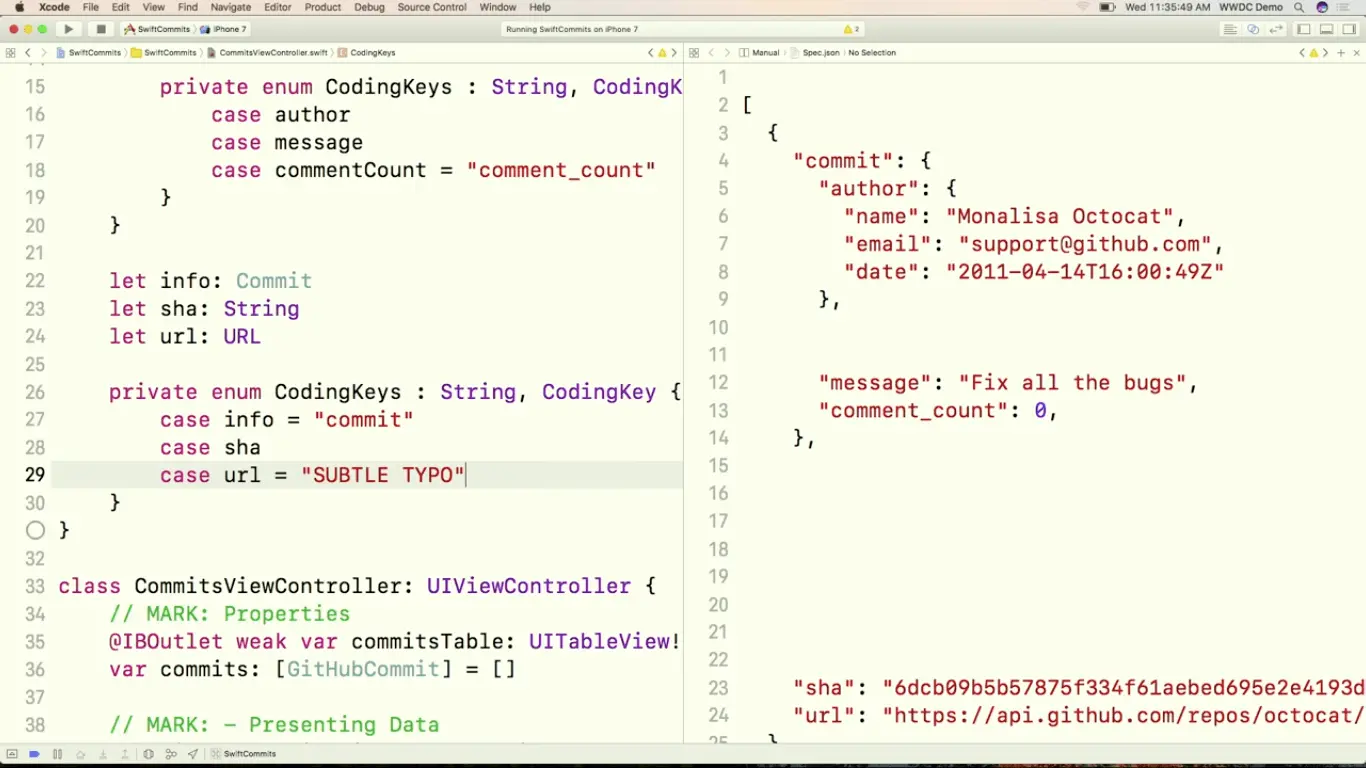
首先我们给 Commit 添加一个 sha 属性,但是编译的时候我们会得到一个编译错误,原因是这样的,GitHubCommit 类型里的 CodingKeys 枚举可以用来控制自动生成的 init(decoder: Decoder) throws 方法的具体实现。
在这里我们把 info 属性映射到 JSON 数据里的 commit 字段,但是,编译器发现我们新增的 sha 属性在 CodingKeys 里没有相应的 case。如果属性有默认值,而且没有写入 CodingKeys 里的话,decode 跟 encode 方法就会自动忽略掉这个属性。
不过由于 sha 属性没有默认值,编译器尝试根据 CodingKeys 为我们生成 init(decoder: Decoder) throws 方法的时候,就会发现 sha 没有合理的值,编译器就会抛出一个错误。
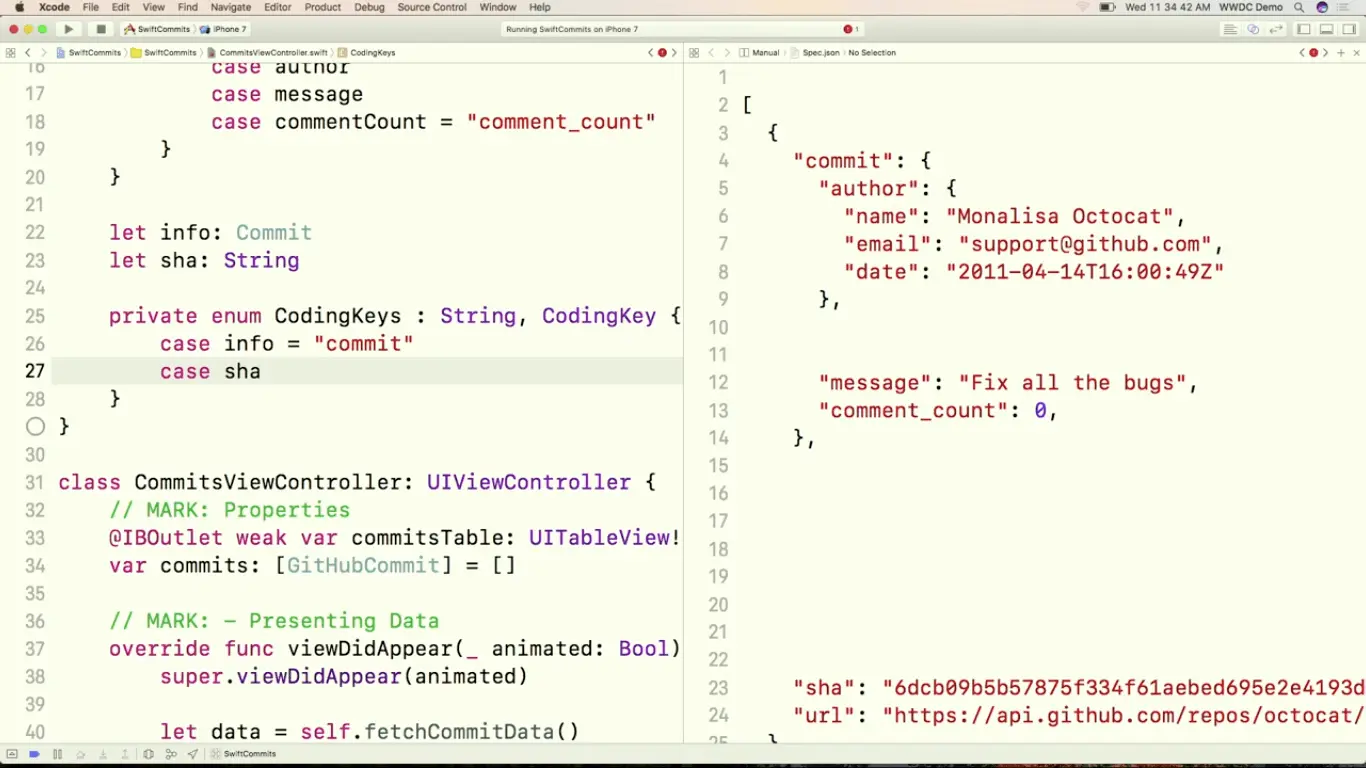
这里我们想让 sha 参与 Decode,所以直接加上相应的 case 就可以了.
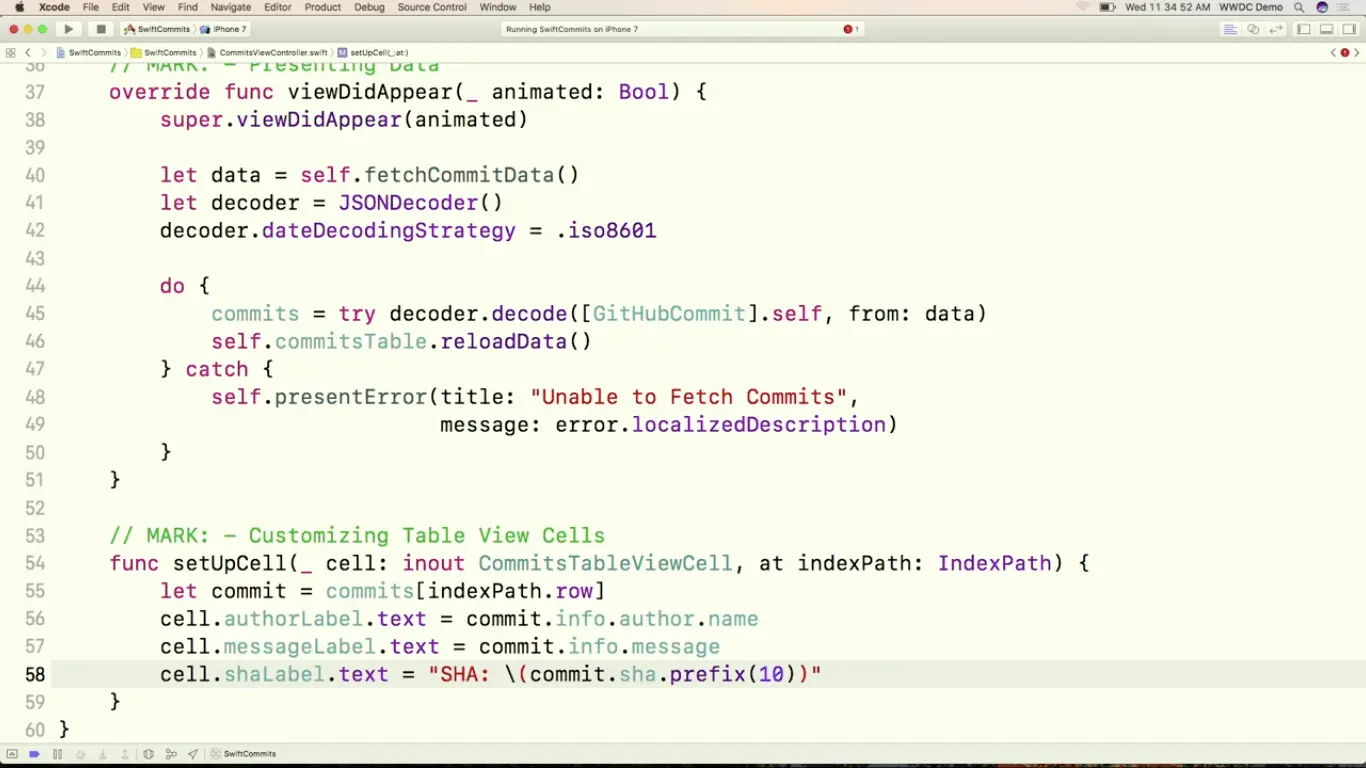
然后我们在 UI 里呈现出来,得到结果:
我们还有最后一个属性没有 decode,让我们完成它
但在这里,我们尝试给 url 一个错误的 rawValue,很明显 JSON 里会找不到相应的 key,decode 的时候会抛出错误.
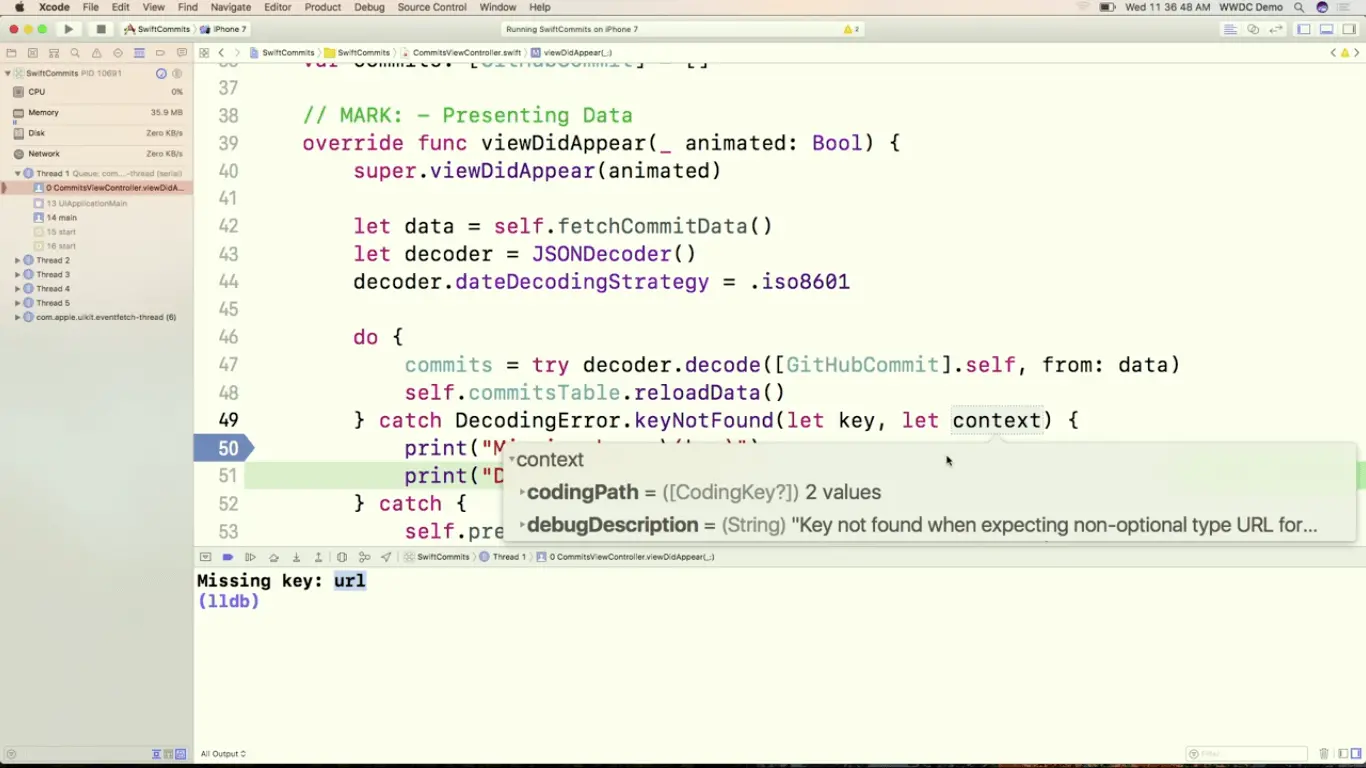
为了处理这个错误,我们尝试捕获 DecodingError.keyNotFound 的错误,这里的 key 是我们尝试访问但找不到的 key,而 context 会告诉我们哪里出错了,里面包含了两个很有用的信息, codingPath 会告诉我们是解析到 JSON 的哪个位置出现这个问题,而 debugDescription 里会解释具体出错的原因。
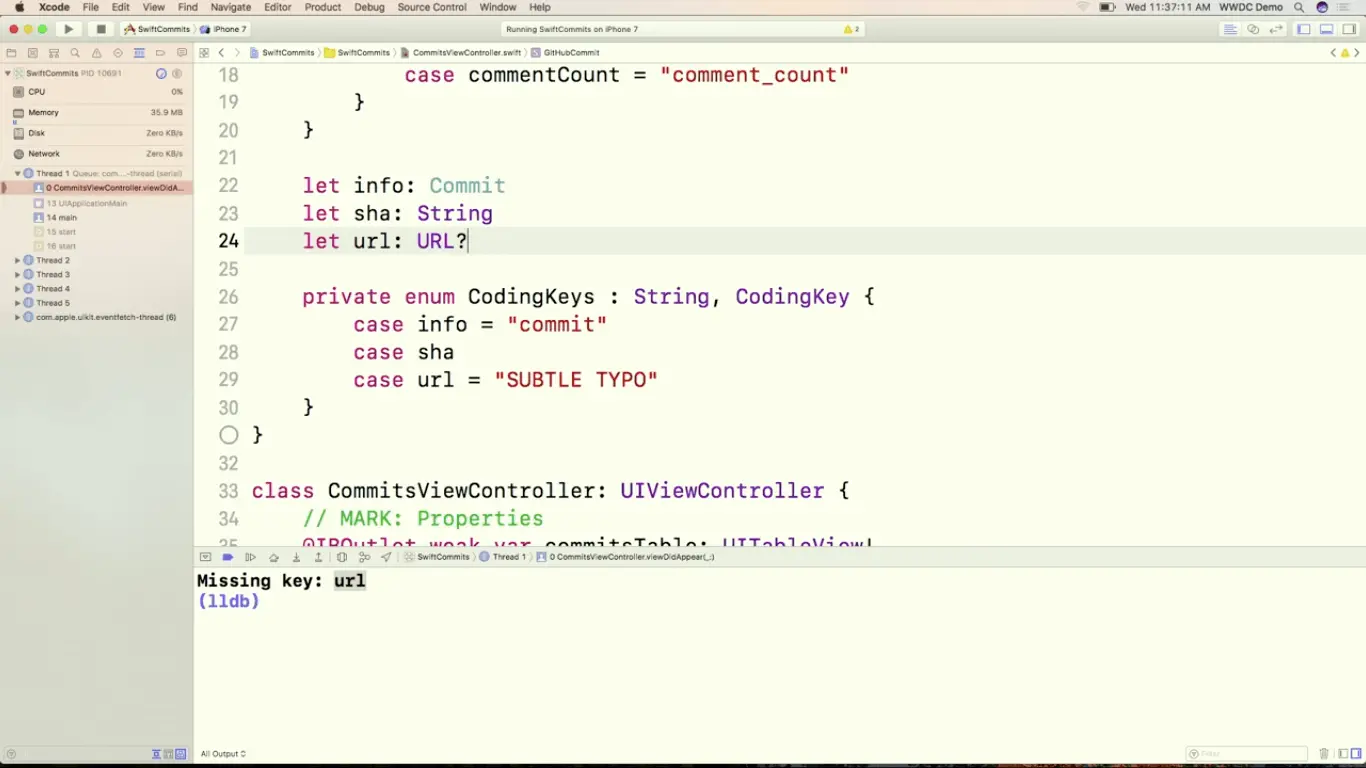
如果我们其实不是很介意 url 在 JSON 里有没有相应的字段的话,可以直接使用 optional,这样相当于给了 url 一个 nil 的默认值。
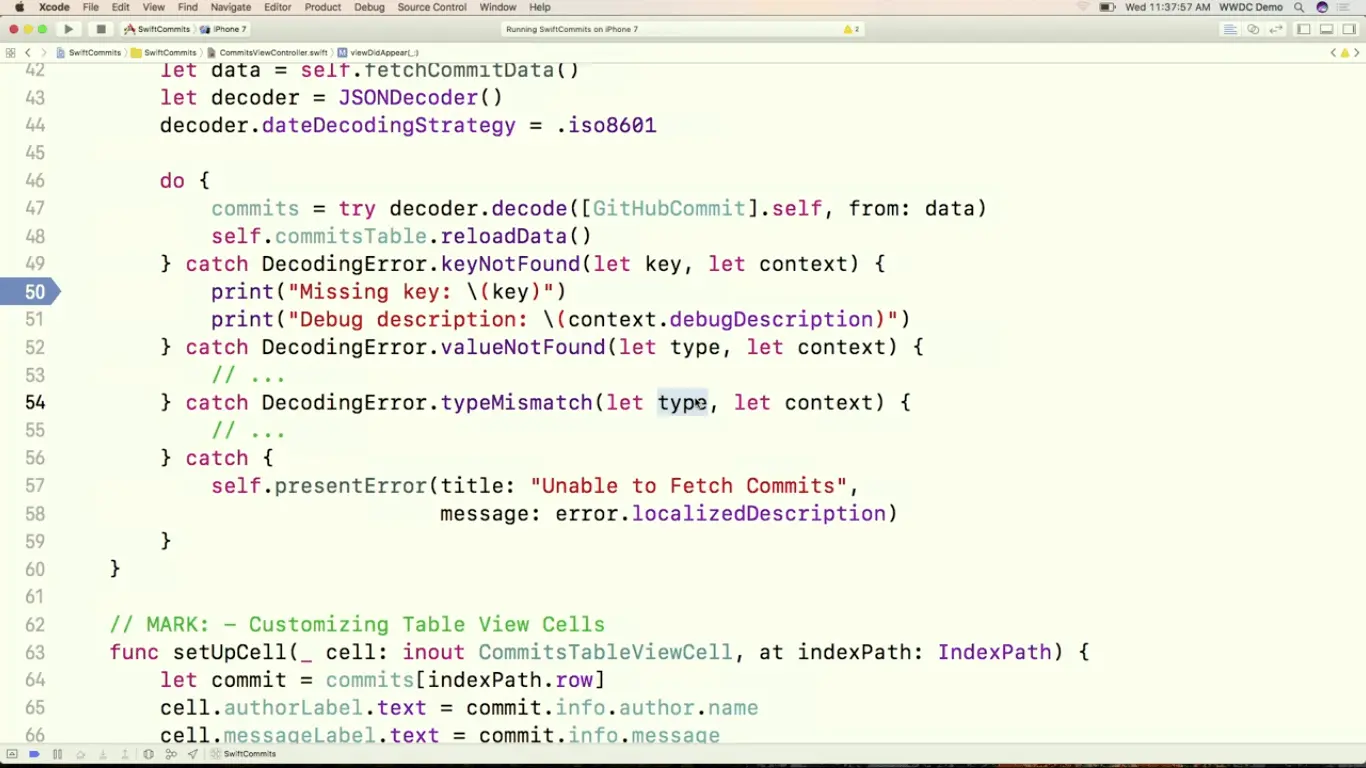
除了 keyNotFound 之后,还有 valueNotFound 找不到相应的值,或者 typeMismatch 值的类型不相符之类的错误。有了这些我们就可以很轻松地定位到错误的地方。
Codable 的哲学
在更进一步解释 Codable 之前,我想引出 Codable 的三个设计哲学思想。
内建错误处理机制
Swift 团队希望编码和解码能够有一套错误处理机制,就像我们刚刚在 demo 里看到的那样
- 处理不合法的输入时,应该是思考“什么时候处理”,而不应该是“该不该处理”。
- 不应该导致崩溃,除非是开发者的错误(注意,不是失误)。错误可能源于 API 改变,数据错误等等,所以决定在处理未知数据时不应该产生崩溃,但如果检测到是由于开发者的错误而导致的解码错误,就还是会 fatalError,而且带上具体的出错原因。
- 编码和解码都可能会产生错误。对于其他错误,我们就使用错误处理机制去解决。
那就首先看一下 Coding 时会产生的 Error:
Encoding 编码
Encoding 很简单,就只有一种错误
- Invalid Value。不合法的值,例如 JSON 就不支持
NaN,infinity,尝试把这些值编码进 JSON 里就会产生这个错误。
Decoding 解码
Decoding 就比较复杂,总共有四种情况,前面三种我们在 demo 里都见过了,最后一种 Data corrupt 主要是用来囊括其它所有情况,前面我们已经看过它的具体用法了。
- Missing key:没有相应的 key。
- Missing value:没有相应的值。
- Type mismatch:类型错误。
- Data corrupt:数据错误。
数据的解码可以分为这么几个阶段:
- Bytes:二进制数据。
- Structured bytes:结构化数据。例如这里是 JSON 的话,就会检查这是不是一段合法的 JSON 数据,首先检查是不是一段字符串,然后格式是否正确,等等一系列的检查,如果不合法的话,JSON decoder 就会在这个阶段抛出错误。
- Typed data:Swift 类型数据。这里会通过结构化数据编码出一个 Swift 的类型实例出来。
- Domain specific validation (可选):数据验证。前面的阶段我们只验证了有没有值,以及值的类型是否正确,那到了这一步,我们就可以验证值的合理性,例如年龄,我们就需要保证它必须在 0 到 100 的范围内。
- Graph-level validation (可选):整体验证。这个时候数据的验证就不局限于数据本身的合法性,而是跟实际情景关联起来,例如我们明明请求的是 Swift 的文档,却返回了 Objective-C 的文档给我们,作为文档本身,它是合理的,可以正常地编码成一个 Swift 类型数据,本身的数据的值也是合理的,但套入到当前的 context 里,它很明显就是一段错误的数据。
那让我们拿之前写过的 Commit 来讲解一下这个过程吧,之前我们讲了如何自定义 CodingKeys 来让属性和数据产生映射关系,现在让我们来自定义 init(from:) throws 方法吧struct Commit : Codable {
struct Author : Codable { ... }
let url : URL
let message : String
let author : Author
let commentCount : Int
private enum CodingKeys : String, CodingKey { ... }
public init(from decoder: Decoder) throw {
let container = try decoder.container(keyedBy: CodingKeys.self)
url = try container.decode(URL.self, forKey: .url)
message = try container.decode(String.self, forKey: .message)
author = try container.decode(Author.self, forKey: .author)
commentCount = try container.decode(Int.self, forKey: .commentCount)
}
}
首先我们通过 decoder,传入 CodingKeys 获取到一个 container,container 会从结构化数据里取与 CodingKeys 对应的那一部分数据。
接着我们从 container 里取出我们所需的数据。这里假设我们需要保证 url 使用的是 https 协议,那我们怎么去验证它呢?public init(from decoder: Decoder) throw {
let container = try decoder.container(keyedBy: CodingKeys.self)
url = try container.decode(URL.self, forKey: .url)
guard url.scheme == "https" else {
throw DecodingError.dataCorrupted(DecodingError.Context(
codingPath : container.codingPath + [CodingKeys.url],
debugDescription : "URL 需要是 https 协议的"))
}
message = try container.decode(String.self, forKey: .message)
author = try container.decode(Author.self, forKey: .author)
commentCount = try container.decode(Int.self, forKey: .commentCount)
}
这里很简单,使用 url 的 api,如果发现不是 https 的话就抛出错误。我们还注意到 url 在 json 里其实是字符串,而且 URL 可以使用这段字符串进行自我解码,如果这段字符串不合法的话,URL 就会抛出错误,然后由于 Swift 的错误处理机制,这个错误最终就会在 url 解析那一行抛出。
封装编码的细节
- 隐藏键值对。我们发现,类型在编码的时候不让类型本身知道,结构化数据里使用了什么类型的键值对,很重要。因为这样可以让我们只关注需要的数据。
- 使用容器来封装数据。Swift 提供了一个中间容器,结构化数据会先塞到容器里,然后再由我们去从容器里取出数据去编码出一个类型数据,这样在编码类型数据的时候就不必了解数据本身到底是使用了 JSON 还是其它什么编码。
Swift 目前只提供了 3 种基础容器:
- Keyed Containers:保存了多个键值对,是大部分情况下的最优选择,因为它有良好的兼容性。
- Unkeyed Containers:用来保持有序的数据。
- Single Value Containers:只保存指向原始数据的指针,这是兼容性最好的一种容器,个人觉得主要是为了保留
container的抽象,然后把这一部分数据转化的过程交给了程序员去完成。
现在让我们来看一下这里的 key 到底是什么?public protocol CodingKey {
var stringValue: String { get }
var intValue: Int? { get }
init?(stringValue: String)
init?(intValue: Int)
}
这里的 stringValue 在应对类似于 JSON 这样的数据时就很有用,而 intValue 主要是对性能要求比较高的时候,使用 intValue 可以优化二进制层面数据,获取到更高的性能表现。private enum CodingKeys : String, CodingKey {
case url
case author
case commentCount = "comment_count"
}
CodingKeys.commentCount.stringValue // "comment_count"
CodingKeys.commentCount.intValue // nil
而平时使用 CodingKey 协议,基本上就是遵守协议,然后让编译器去完成解析来的工作就可以了,在这我们可以看到 stringValue 基本上就是枚举 case 的名字,而 intValue 因为枚举的原始值是 String 所以为 nil。
而在我们自定义 case 名之后,stringValue 还是不变,保持 GitHub API 里的数据一致。private enum CodingKeys : String, CodingKey {
case url = 22
case author = 100
case comment_count
}
CodingKeys.commentCount.stringValue // "comment_count"
CodingKeys.commentCount.intValue // 101
如果你是在封装库的话,就更加推荐使用 Int 来作为原始值,会有更好的性能表现。
实例讲解
接下来我们通过再回到 Commit 的例子里,之前我们看了 CodingKeys 以及 init(from:) throws 的实现,现在来看一下 encode(to:) throws:struct Commit : Codable {
struct Author : Codable { ... }
let url : URL
let message : String
let author : Author
let commentCount : Int
private enum CodingKeys : String, CodingKey { ... }
public init(from decoder: Decoder) throw { ... }
public func encode(to encoder: Encoder) throws {
var container = encoder.container(keyedBy: CodingKeys.self)
try container.encode(url, forKey: .url)
try container.encode(message, forKey: .message)
try container.encode(author, forKey: .author)
try container.encode(commentCount, forKey: .commentCount)
}
}
这里没有做什么自定义的东西,跟编译器产生的实现其实是一样的,主要是为了让大家更了解这整个过程:
- 传入
CodingKeys.self构建container - 将值编码到相应的 key 里
过程很简单,接下来展示什么时候该使用别的 Container:struct Point2D : Encodable {
var x : Double
var y : Double
public func encode(to encoder: Encoder) throws {
var container = encoder.unkeyedContainer()
try container.encode(x)
try container.encode(y)
}
}
// 编码后的数据 [ 1.5, 3.9 ]
这里是一个平面的坐标,数据简单,那 unkeyedContainer 就是个不错的选择。
Nested Containers
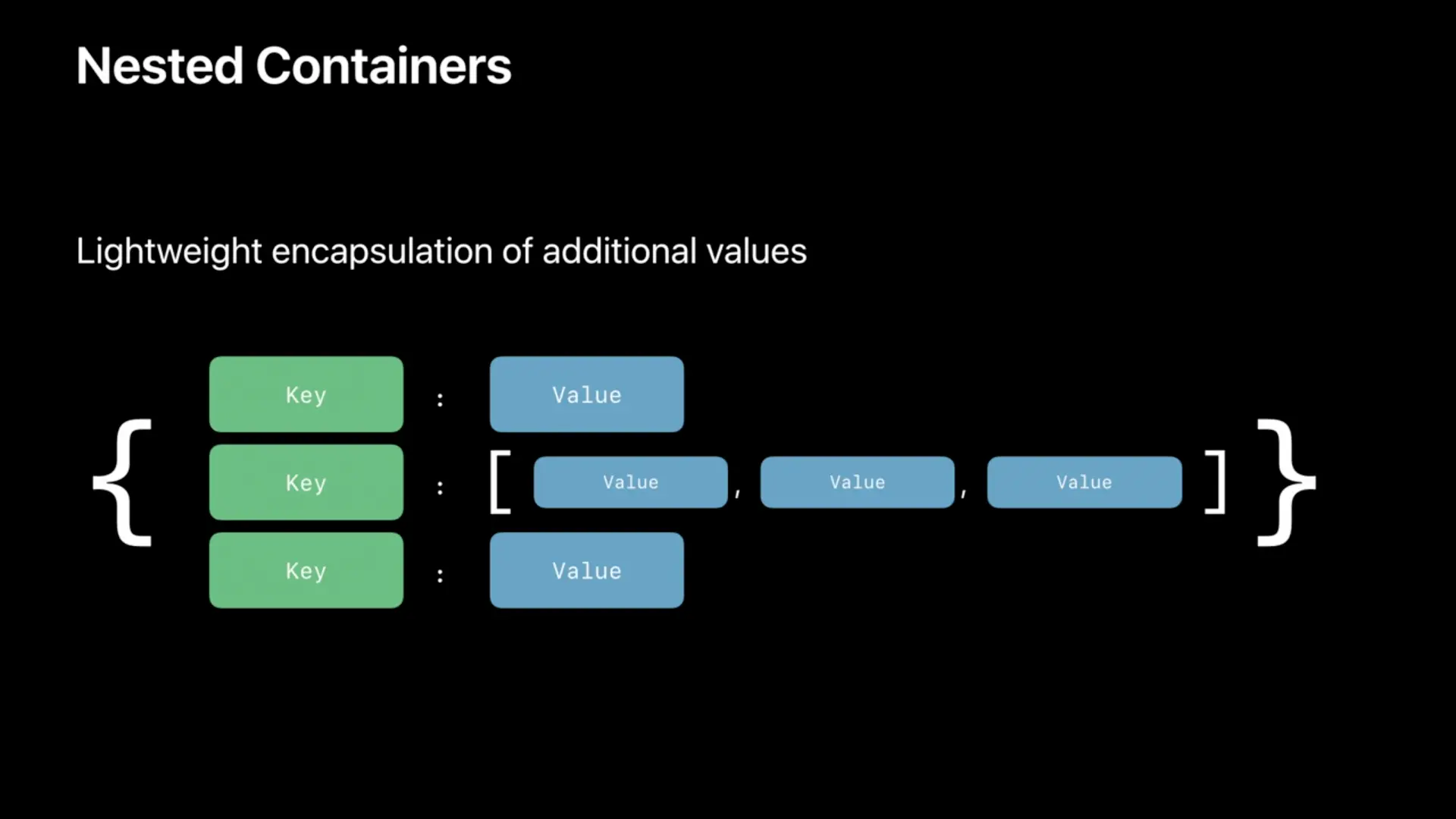
还有就是复合结构容器,支持上面三种基本容器的嵌套。
这样的设计主要是为了支持继承,让继承关系也能编码起来,而且也在每一层都把父类的信息都可以封装得很好。class Animal : Codable {
var legCount: Int
private enum CodingKeys: String, CodingKey { case legCount }
required init(from decoder: Decoder) throws {
let container = try decoder.container(keyedBy: CodingKeys.self)
legCount = try container.decode(Int.self, forKey: .legCount)
}
}
class Dog : Animal {
var bestFriend : Kid
private enum CodingKeys : String, CodingKey { case bestFriend }
required init(from decoder: Decoder) throws {
let container = try decoder.container(keyedBy: CodingKeys.self)
bestFriend = try container.decode(Kid.self, forKey: .bestFriend)
let superDecoder = try container.superDecoder()
try super.init(from: superDecoder)
}
}
这里我们有两个类,Animal 以及它的子类 Dog。这里由于 CodingKeys 是 private 的,所以父类和子类不会产生冲突。
前面初始化 bestFriend 的方法还是跟之前一样,然后只要 container 调用方法 superDecoder 就能获得父类所需的 decoder,传入 super.init(from:) 里就可以完成操作了。
把类型的模样抽象出来
- 复用 Encodable 和 Decodable 的一种实现。到现在我们发现,其实我们一直用的都是同一套实现,只是每个类型具体的属性不同而已,把类型的样式抽象出来之后,我们就可以一直复用同一套实现了。
- 就算类型发生改变,但生成 Codable 实现的实现并不需要跟着做改变。我们其实是写了一套实现去生成具体的实现,做到了更加高级的抽象。
- 不同的格式,对应着不同的元类型和解码形式。我们可以自定义特定类型的编码和解码形式。
受益于这套灵活的方案,Foundation 里这些奇奇怪怪的类型其实都是遵循 Codable 协议的。
总结
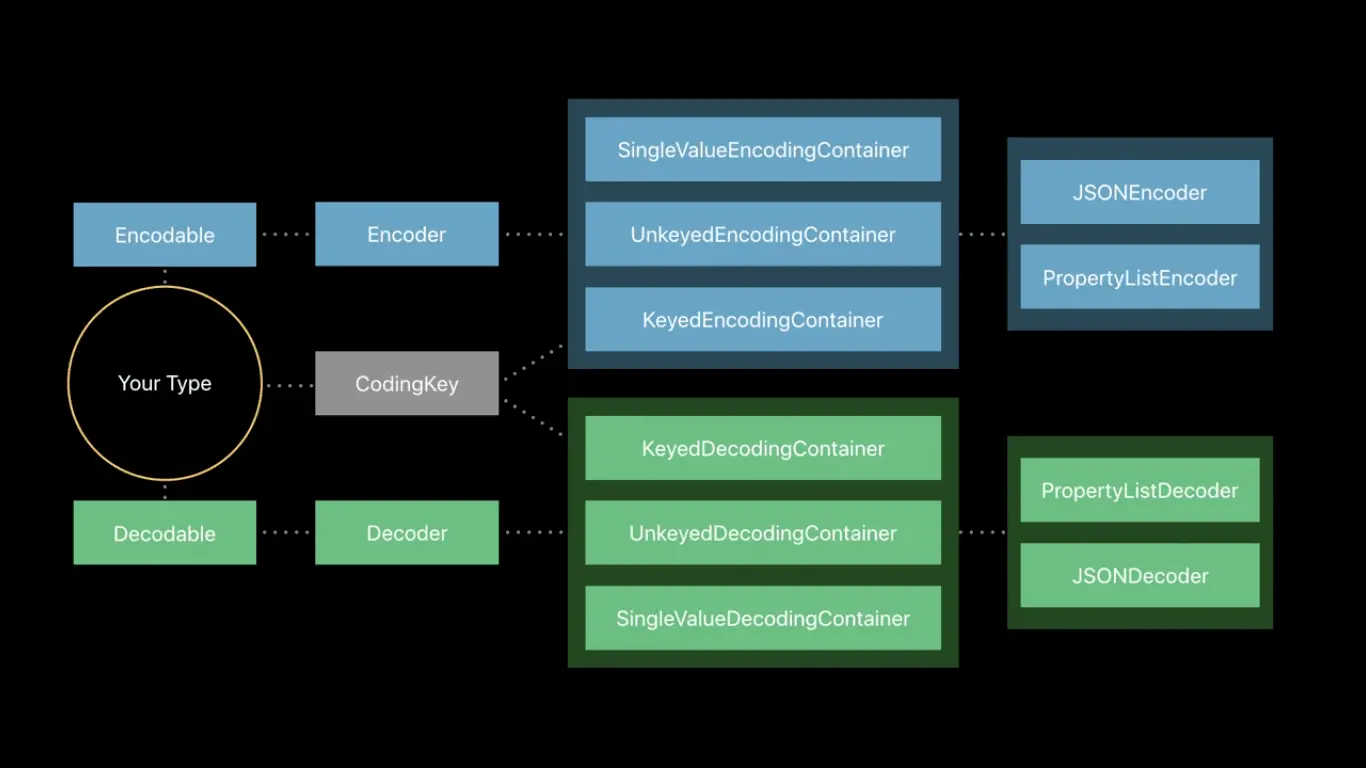
首先从我们的类型开始,遵循 Encodable/Decodable 协议,在初始化方法里获取到 Encoder/Decoder,然后我们就能获取到实际存储数据的 Container,而 KeyedEncodingContainer/KeyedDecodingContainer 再通过 CodingKey 插入/获取值,最后 Container 再借助 Encoder 获取到编码的具体格式。