WWDC 2018 - What's New in Swift?
这个 Session 分为两个部分,前半部分会简单介绍一下 Swift 开源相关的事情,后半部分我们深入了解一下 Swift 4.2 带来了哪些更新。
社区的发展
首先我们来看一下 Swift 的一些统计数据,Swift 自开源之后,总共有 600 个代码贡献者,合并了超过 18k pull request。

社区主导的持续集成
Swift 想要成为一门跨平台的泛用语言,大概一个月之前,Swift 团队拓展了原有的公开集成平台,叫做 Community-Hosted Continuous Integration,如果大家想要把 Swift 带到其它平台上,就可以在这上面去接入你们自己的硬件机器,Swift 会定期在这些硬件上跑一遍集成测试,这样大家就可以非常及时地了解到最新的 Swift 是否能在你们的平台上正常运行。

Swift 论坛
同时,Swift 的团队付出了很大的精力在维护 Swift 的社区上,两个月前 Swift 社区正式从邮件列表转向论坛,让大家可以更容易贡献自己的力量,例如说三月份的这一份提案:
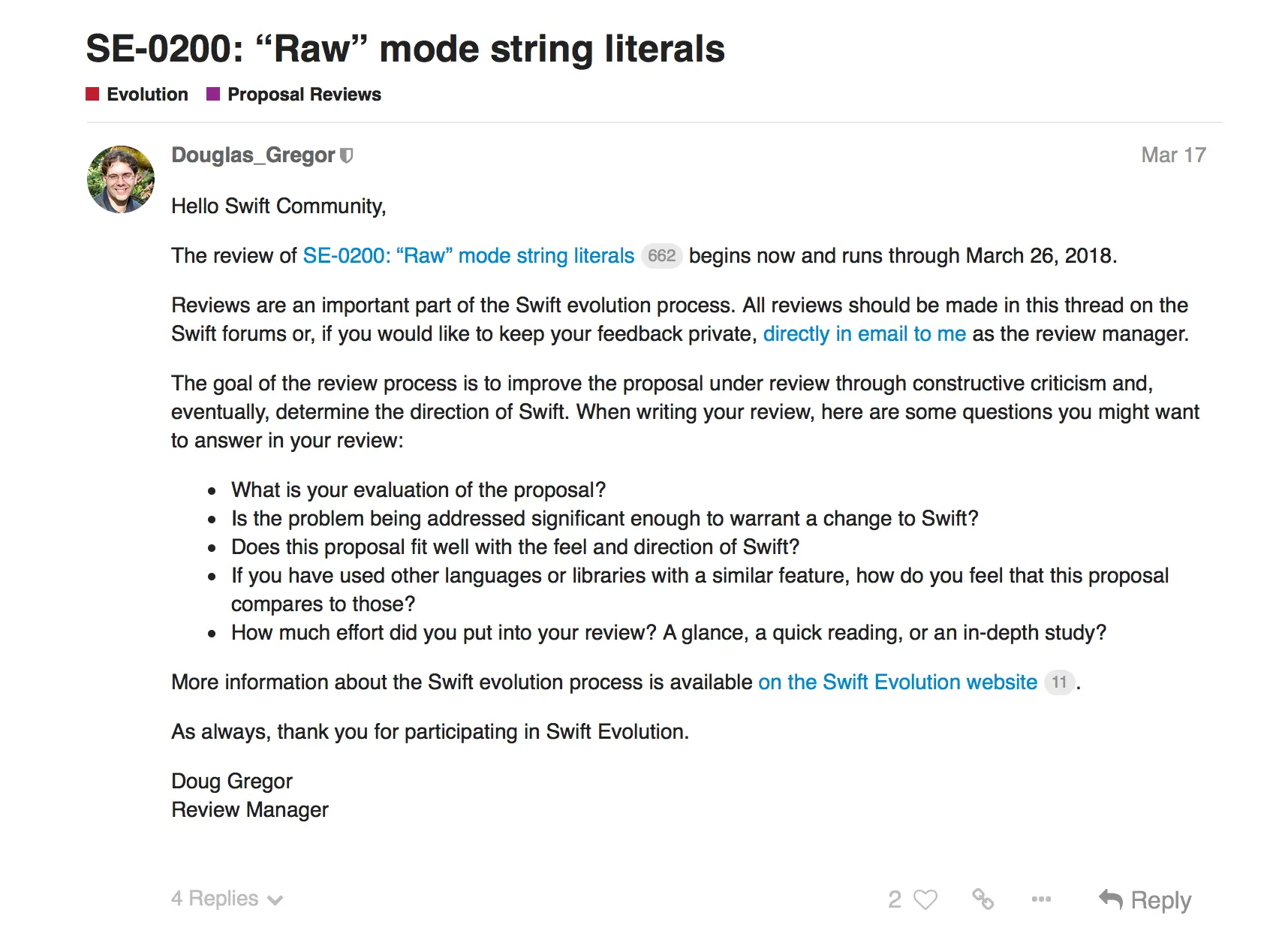
大家只要简单回答这些问题,参与讨论即可,如果你对于这方面的理解不深,不想贸然发言的话,其实只要大概阅读过社区成员们的发言,对这件事情有了解,那也是一种参与,以后也许这个提案出来了你还可以写篇文章跟大家讲讲当时讨论的内容和要点。
如果你在维护一个 Swift 相关的计划,你可以考虑在论坛上申请一个板块,让社区的人也可以关注到你的计划并且参与到其中来。
Swift 的文档现在改为由 swift.org 来维护,网址是 docs.swift.org。
Chris Lattner
Chris Lattner 大神离开苹果的时候,有很多人在讨论 Swift 是不是已经没戏了,但过去一年,实际上 Chris 为 Swift 做了很多,去谷歌甚至可以说是去那里做 Swift 布道师。
Chris 进了谷歌之后,谷歌 fork 了一个 Swift 的仓库,作为谷歌里开发者 Commit 的中转站,过去一年修复了很多 Swift 在 Linux 上的运行问题,让 Swift 在 Linux 上的运行更加稳定。谷歌还写了一个 Swift Formatter,现在正在开发阶段。
并且与 Tensorflow 紧密合作,开发了 Swift for Tensorflow,主要是因为 python 已经渐渐无法满足 Tensorflow 的使用,上百万次的学习循环让性能表现变得异常重要,需要一门语言去跟 Tensorflow 有更紧密的交互,大家可能觉得其它语言也都可以使用 Tensorflow,没有什么特别,实际上其它语言都只是开发了 Tensorflow 的 API,而 Swift 代码则会被直接编译成 Tensorflow Graph,具有更强的性能,甚至 Tensorflow 团队还为 Swift 开发了专门的语法,让 Swift 变成 Tensorflow 里的一等公民。加入了与 Python 的交互之后,让 Swift 在机器学习领域得到了更加好的生态。
Chris 在过去一年,拉谷歌入局一起维护 Swift,加强 Swift 在 Linux 上的表现,还给 Swift 开辟了一个机器学习的领域,并且在 Swift 社区持续活跃贡献着自己的才华,现在我想大家完全可以不必担心说 Chris 的离开会对 Swift 产生什么不好的影响。
What is Swift 4.2?
接下来我们要了解一下 Swift 4.2,那么 Swift 4.2 是什么呢?它在整个开发周期中是一个什么样的角色?

Swift 每半年就会有一次 Major Release,Swift 4.2 就是继 4.0 和 4.1 之后的一次 Major Release,官方团队一直致力于提升开发体验:
- 更快的编译速度
- 增加功能提升代码编写效率
- SDK 对于 Swift 更好的支持
- 提升 ABI 的兼容性

Swift 5 会在 2019 年前期正式发布,ABI 最终会在这一个版本里稳定下来,并且 Swift 的运行时也会内嵌到操作系统里,到时候 App 的启动速度会有进一步的提升,并且打包出来的程序也会变得更小。
如果大家对于 ABI 稳定的计划感兴趣的话,可以关注一下这一份进度表 ABI Dashboard。
编译器的改进
代码兼容性
跟 Xcode 9 一样,Xcode 10 里也只会搭载一个 Swift 编译器,并且提供两种兼容模式,同时兼容之前的两个 Swift
版本,这三种模式都可以使用新的 API,新的语言功能。

并且不只是 Swift 的语法层面的兼容,开发组三种模式也同时覆盖 SDK 的兼容,也就是说只要你的代码在 Xcode 8,Swift 3 的环境下能跑,那么在 Xcode 10 里使用兼容模式也肯定可以跑起来。
但 Swift 4.2 确实提供了更多优秀的功能,为了接下来的开发,这会是最后一个支持 Swift 3 兼容模式的版本。
更快的 Debug 编译速度
接下来我们来讨论一下编译速度的提升,这是在 Macbook Pro 四核 i7 上测试现有 App 的结果:
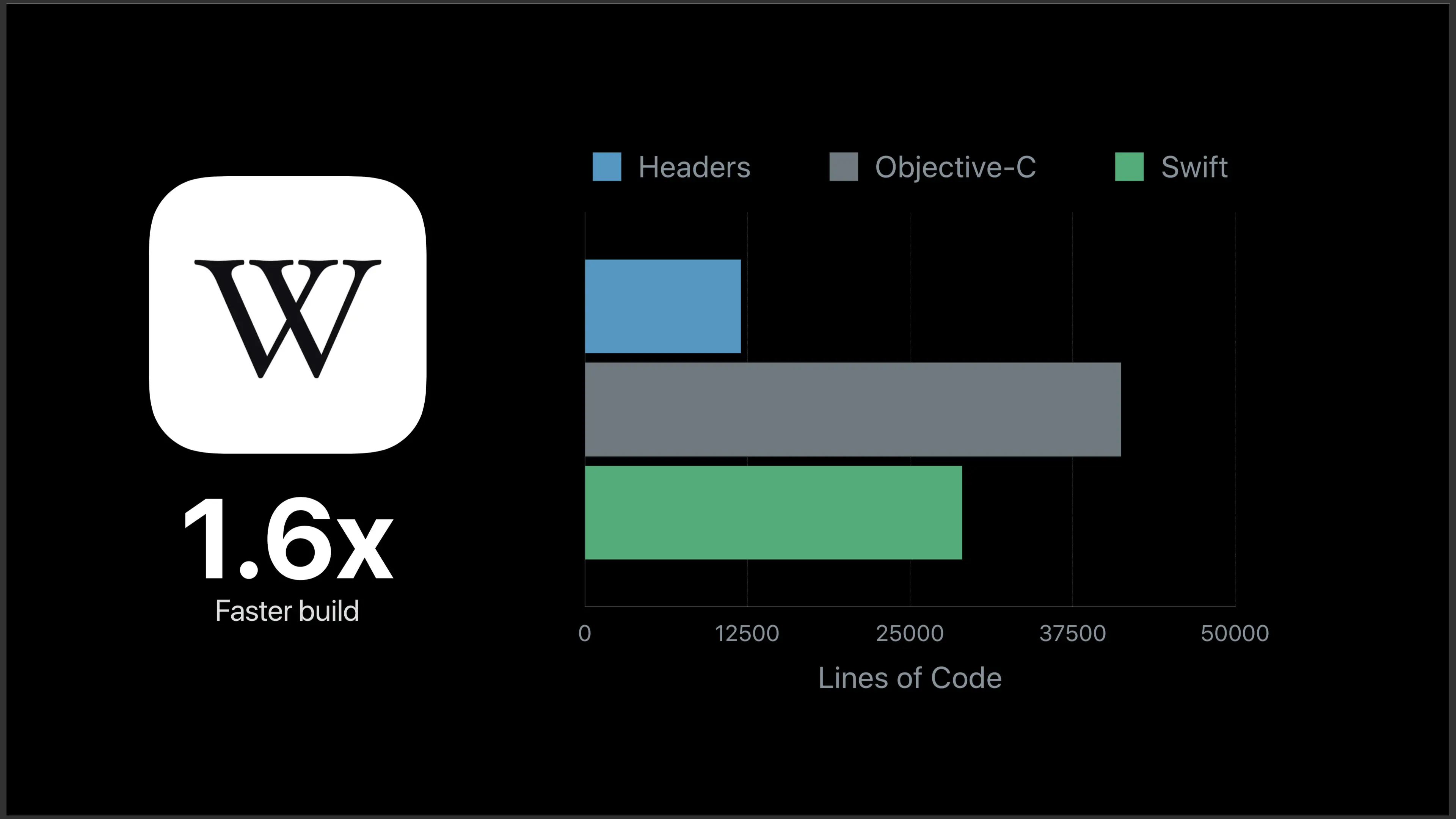
Wikipedia 是一个 Objective-C 和 Swift 混编的项目,可能更加贴近大家的实际项目,项目的编译速度实际上取决于很多方面,例如说项目的配置,图片文件的数量跟大小。
1.6 倍的提升是整体的速度,如果我们只关注 Swift 的编译时间的话,实际上它总共提升了 3 倍,对于很大一部分项目来说,一次全量编译大概可以比以前快两倍。
这些提升来自于哪里呢?由于 Swift 里并不需要导入头文件,但每一个文件由可以访问到模块里的其他文件里的内容,所以编译阶段会有大量的重复工作去进行 symbol 查找,这次编译器构建了一个编译 pipeline 去减少重复的跨文件执行。
Compilation Mode vs. Optimization Level

另外这一次,把“编译模式”从“优化级别”里剥离了出来,编译模式意味着我们如何编译我们的模块,目前总共有两种模式:
- 增量化编译(Incremental):也就是以前的 Single File,逐个文件编译。
- 模块化编译(Whole Module):整个模块一起编译。
增量编译虽然全量编译一次会比模块化编译慢,但是之后修改一次文件就只需要再编译一次相关的文件即可,而不必整个模块都重新编译一次。
整个模块一起编译的话会更加快,据说原理是把所有文件都合并为一个文件,然后再进行编译,以此减少跨文件的 symbol 查找。但一旦改动了其中一个文件,就需要重新再把整个模块编译一遍。
增加了这个编译选项实际上还有一个很重要的意义,以前我们只有三种选项,可以达到下面三种效果:
| 增量化编译 | 模块化编译 | |
|---|---|---|
| 优化 | ✅ | ✅ |
| 不优化 | ✅ | ❌ |
优化是需要消耗时间的的,现在我们可以使用模块化并且不优化的选项,达到最快的编译速度,把这个选项应用到我们项目里不经常改动的那一部分代码里的话(例如 pod 的依赖库),就可以大大提高我们的编译速度。
我这个配置应用到项目里之后,实测编译速度从 113s 加快到了到了 64s,只要在 podfile 里加入这一段代码就可以了(在 Xcode 9.3 也可以正常使用):post_install do |installer|
# 提高 pod 库编译速度
installer.pods_project.targets.each do |target|
target.build_configurations.each do |config|
config.build_settings['SWIFT_COMPILATION_MODE'] = 'wholemodule'
if config.name == 'Debug'
config.build_settings['SWIFT_OPTIMIZATION_LEVEL'] = '-Onone'
else
config.build_settings['SWIFT_OPTIMIZATION_LEVEL'] = '-Osize'
end
end
end
end
Runtime 优化
ARC
Swift 使用 ARC 进行内存管理,ARC 是在 MRC 的基础上演进出来的,ARC 使用某种对象管理模型在编译时,在合适的位置自动为我们插入 retain 跟 release 代码。
Swift 4.2 之前使用的模型是“持有(owned)”模型,调用方负责 retain,被调用方负责 release,换句话就是说被调用方持有了传进来的对象,如下图所示:
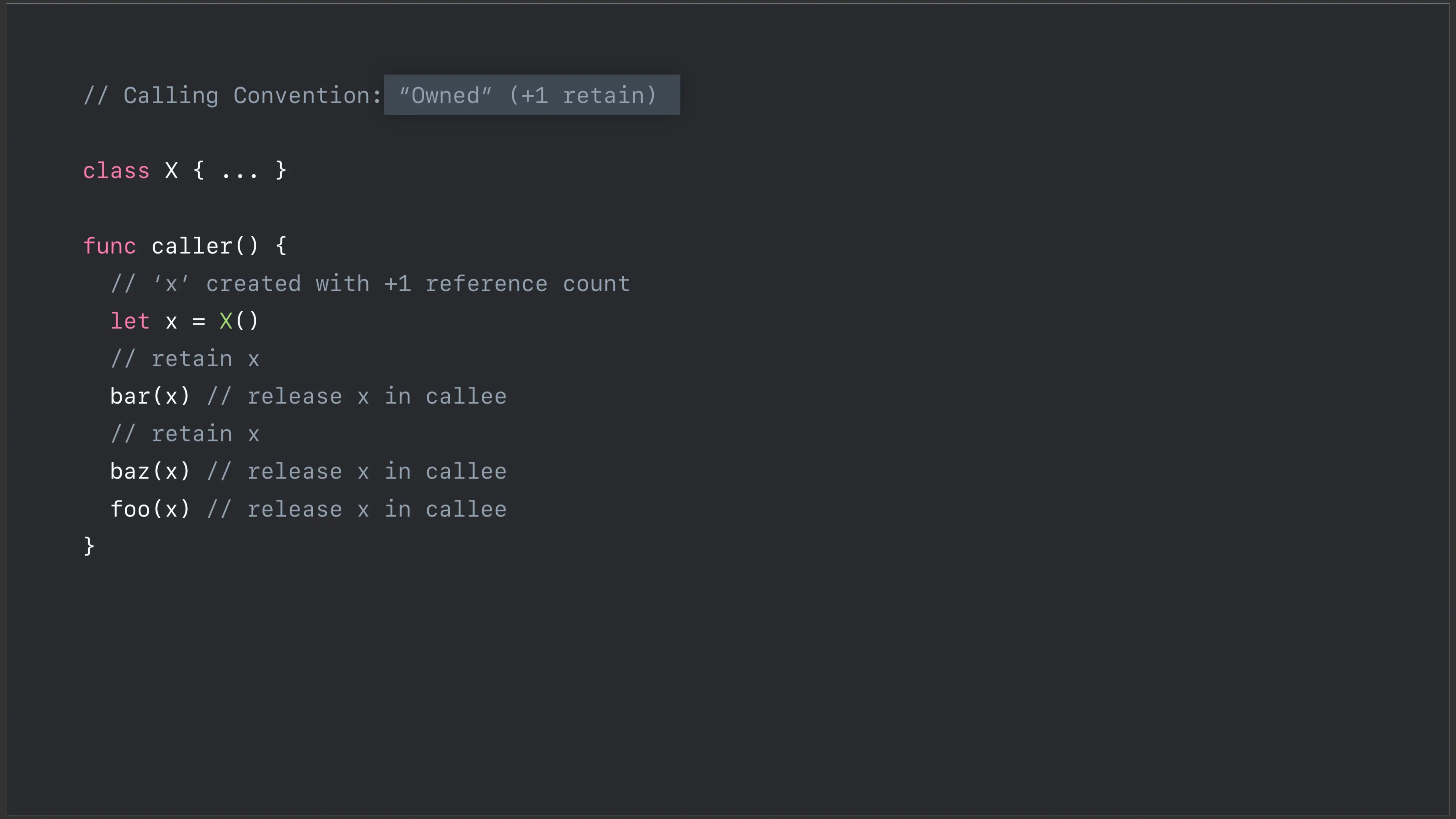
但实际上这种模型会产生很多不必要的 retain 跟 release,现在 Swift 4.2 改为使用**“担保(Guaranteed)”模型,由调用方**去保证对象在函数调用的生命周期内不会被 release 掉,被调用方不再持有对象:
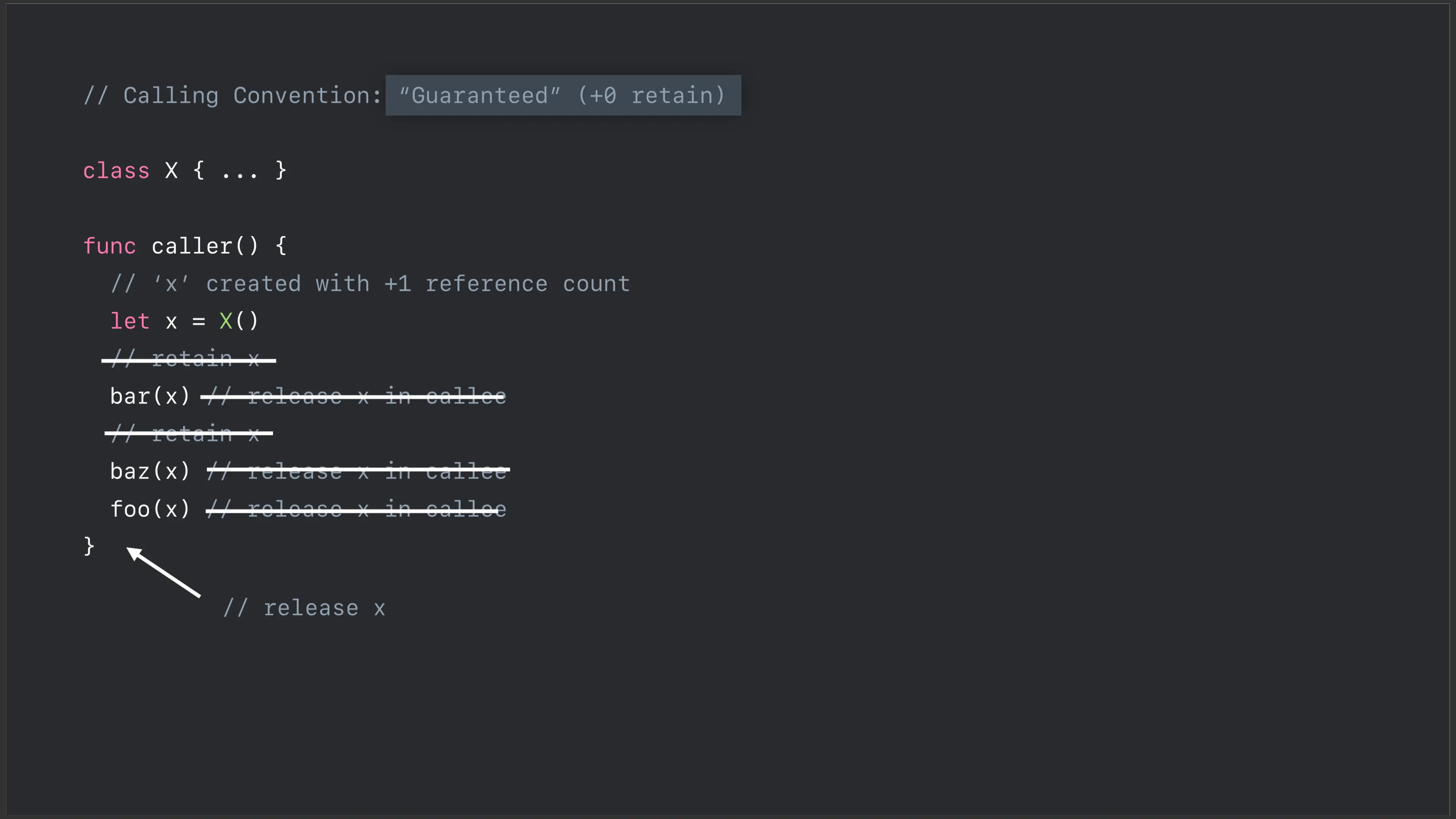
采取了这种模型之后,不止可以有更好的性能表现,还会让编译出来的二进制文件变得更小。
String

当我们在 64bit 的平台上实例化一个 String 的时候,它的长度是 16 bytes,为了存储不等长的内容,它会在堆里申请一段空间去存储,而那 16 个 bytes 里会存储着一些相关信息,例如编码格式,这是权衡了性能和内存占用之后的出来的结果。
但 16 bytes 的内存占用实际上还存在着优化空间,对于一些足够小的字符串,我们完全可以不必在堆里独立存储,而是放到这 16 个 bytes 里空余的部分,这样就可以让小字符串有更好的性能和更少的内存占用。
具体原理跟 NSString 的 Tagged Pointer 一样,但能比 NSString 存放稍微更大一点的字符串。
减小代码尺寸
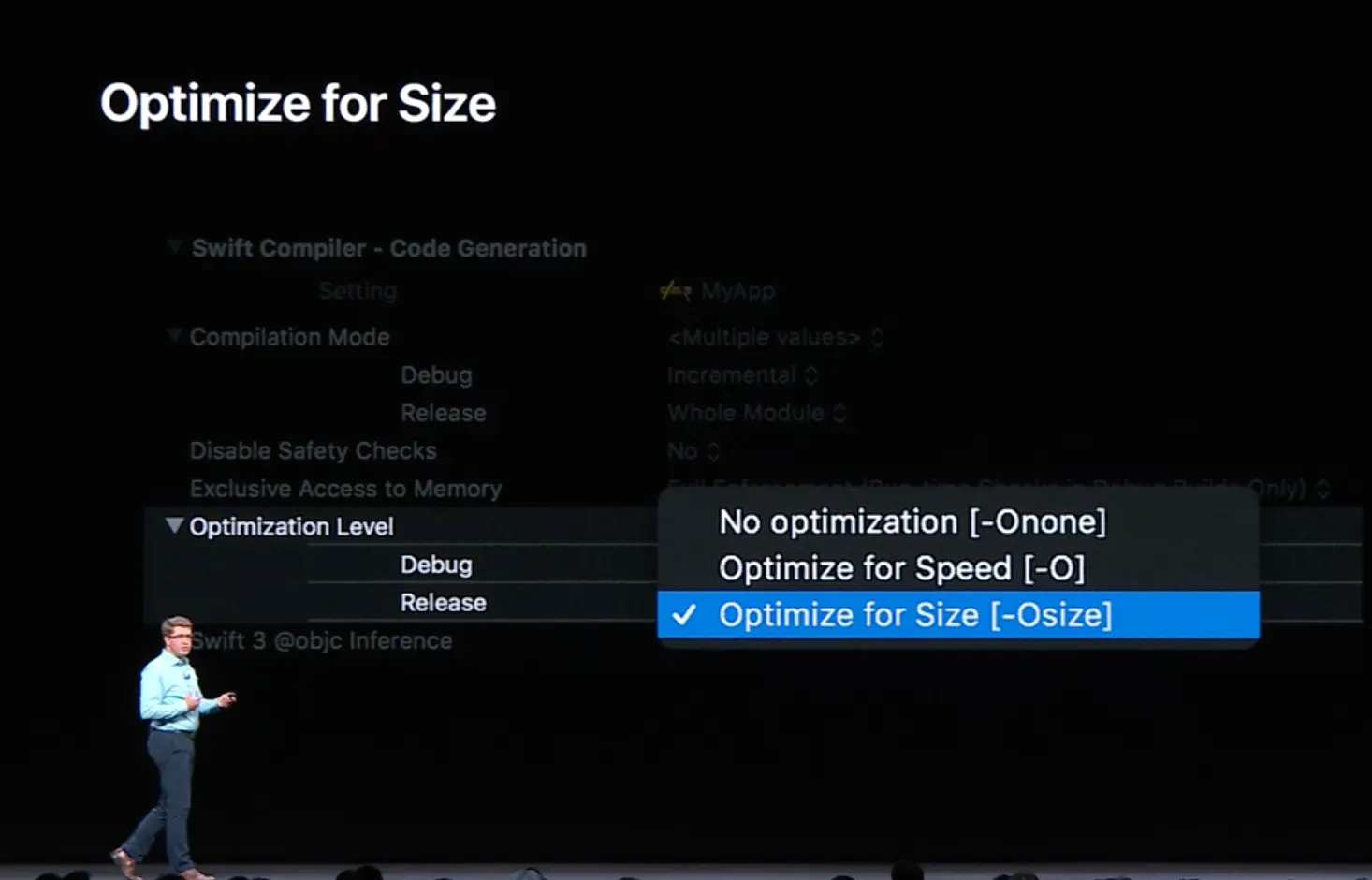
Swift 还增加了一个优化等级选项 “Optimize for Size”,名如其意就是优化尺寸,编译器通过减少泛型特例化,减少函数内联等等手段,让最终编译出来的二进制文件变得更小
现实中性能可能并非人们最关心的,而应用的大小会更加重要,使用了这个编译选项实测可以让二进制文件减小 10-30%,而性能通常会多消耗 5%。
新的语法功能
可遍历枚举
以前我们为了遍历枚举值,可能会自己去实现一个 allCases 的属性:enum LogLevel {
case warn
case info
static let allCases: [LogLevel] = [.warn, .info]
}
但我们在添加新的 case 的时候可能会忘了去更新 allCases,现在我们在 Swift 4.2 里可以使用 CaseIterable 协议,让编译器自动为我们创建 allCases:enum LogLevel: CaseIterable {
case warn
case info
}
for level in LogLevel.allCases {
print(level)
}
Conditional Conformance
Conditional Conformance 表达了这样的一个语义:泛型类型在特定条件下会遵循一个特定的协议。例如,Array 只会在它的元素为 Equatable 的时候遵循 Equatable:extension Array: Equatable where Element: Equatable {
func ==<T : Equatable>(lhs: Array<Element>, rhs: Array<Element>) -> Bool { ... }
}
这是一个非常强劲的功能,Swift 标准库里大量使用这个功能,Codable 也是通过这个功能去进行检查,帮助我们自动生成解析代码的.
Hashable 的加强
与 Codable 类似,Swift 4.2 为 Equatable 和 Hashable 引入了自动实现的功能:struct Stock: Hashable {
var market: String
var code: String
}
但这会带来一个问题,hashValue 该怎么实现?现有 hashValue 的 API 虽然简单,但却难以实现,你必须想出一种方法去把所有属性糅合起来然后产生一个哈希值,并且像 Set 和 Dictionary 这种围绕哈希表构建起来的序列,性能完全依赖于存储的元素的哈希实现,这是不合理的。
在 Swift 4.2 里,改进了 Hashable 的 API,引入了一个新的 Hasher 类型来存储哈希算法,新的 Hashable 长这个样子:protocol Hashable {
func hash(into hasher: inout Hasher)
}
现在我们不需要在实现 Hashable 的时候就决定好具体的哈希算法,而是决定哪些属性去参与哈希的过程:extension Stock: Hashable {
func hash(into hasher: inout Hasher) {
market.hash(into: &hasher)
code.hash(into: &hasher)
}
}
这样 Dictionary 就不再依赖于存储元素的哈希实现,可以自己选择一个高效的哈希算法去构建 Hasher,然后调用 hash(into:) 方法去获得一个哈希值。
Swift 会在每次运行时 为 Dictionary 和 Set 提供一个随机的种子去产生随机数作为哈希的参数,所以 Dictionary 和 Set 都不再是一个有序的集合,如果你的代码里依赖于它们的顺序的话,那就会产生问题了。
而如果你希望使用一个自定义的随机种子的话,可以使用环境变量 SWIFT_DETERMINISTIC_HASHING 去控制:
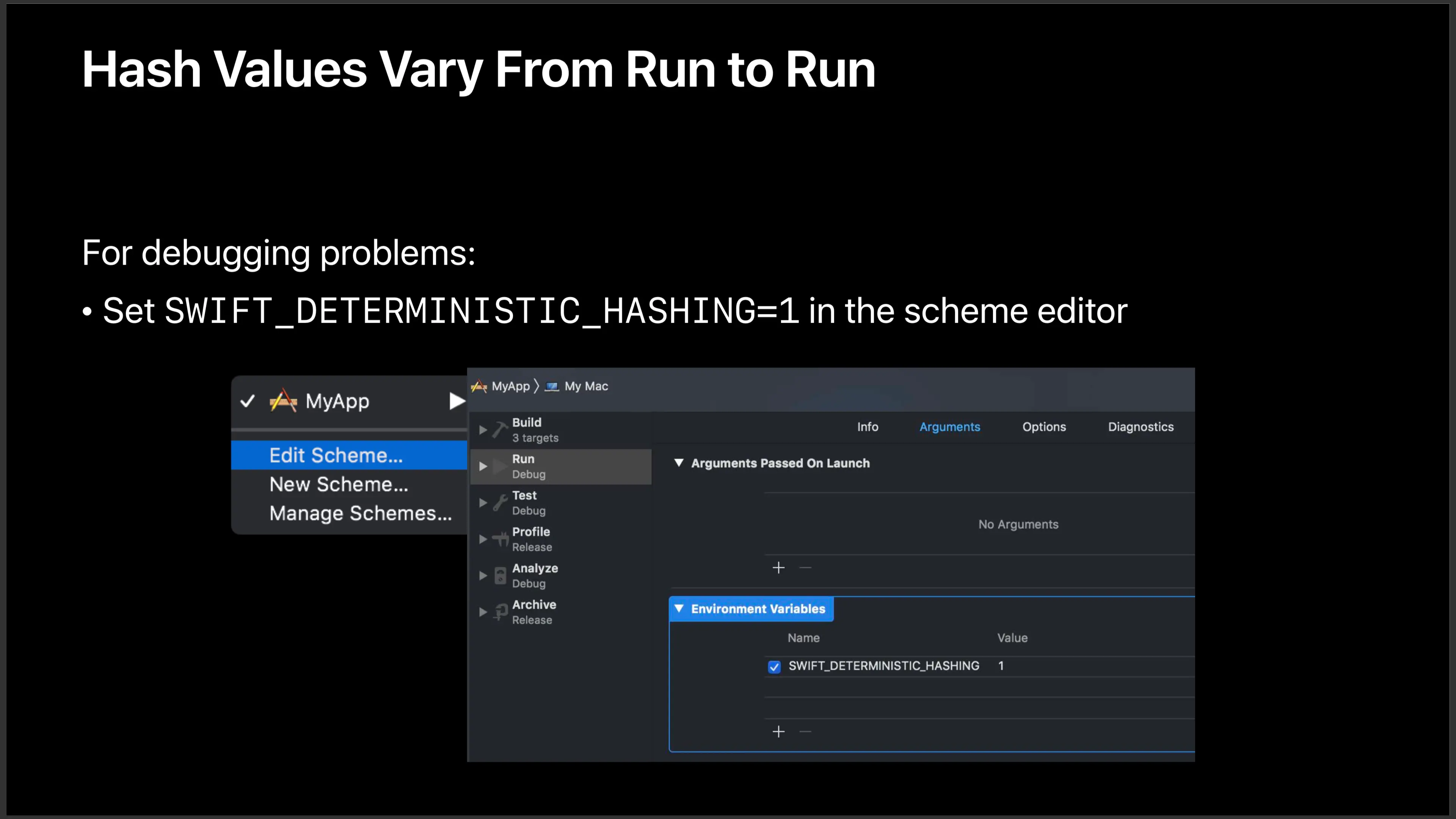
更多细节可以查看 SE-0206 提案,不是很长,建议大家阅读一遍。
随机数产生
随机数的产生是一个很大的话题,通常它都需要系统去获取运行环境中的变量去做为随机种子,这也造就了不同平台上会有不同的随机数 API:#if os(iOS) || os(tvOS) || os(watchOS) || os(macOS)
return Int(arc4random())
#else
return random()
#endif
但开发者不太应该去关系这些这么琐碎的事情,虽然 Swift 4.2 里最重要的是 ABI 兼容性的提升,但还是实现了一套随机数的 API:let randomIntFrom0To10 = Int.random(in: 0 ..< 10)
let randomFloat = Flow.random(in: 0 ..< 1)
let greetings = ["hey", "hi", "hello", "hola"]
print(greetings.randomElement()!)
let randomlyOrderGreetings = greetings.shuffled()
print(randomlyOrderedGreetings)
我们现在可以简单地获取一个随机数,获取数组里的一个随机元素,或者是把数组打乱,在苹果的平台上或者是 Linux 上随机数的产生都是安全的。
并且你还可以自己定义一个随机数产生器:struct CustomRandomNumberGenerator: RandomNumberGenerator { ... }
var generator = CustomRandomNumberGenerator()
let randomIntFrom0To10 = Int.random(in: 0 ..< 10, using: &generator)
let randomFloat = Flow.random(in: 0 ..< 1, using: &generator)
let greetings = ["hey", "hi", "hello", "hola"]
print(greetings.randomElement(using: &generator)!)
let randomlyOrderGreetings = greetings.shuffled(using: &generator)
print(randomlyOrderedGreetings)
检测目标运行平台
以往我们自定义一些跨平台的代码的时候,都是这么判断的:#if os(iOS) || os(watchOS) || os(tvOS)
import UIKit
typealias Color = UIColor
#else
import AppKit
typealias Color = NSColor
#endif
extension Color { ... }
但实际上我们关心的并不是到底我们的代码能跑在什么平台上,而是它能导入什么库,所以 Swift 4.2 新增了一个判断库是否能导入的宏:#if canImport(UIKit)
import UIKit
typealias Color = UIColor
#elseif canImport(AppKit)
import AppKit
typealias Color = NSColor
#else
#error("Unsupported platform")
#endif
并且 Swift 还新增了一套编译宏能够让我们在代码里手动抛出编译错误 #error("Error") 或者是编译警告 #warn("Warning")(以后不再需要 FIXME 这种东西了)。
另外还增加了一套判断运行环境的宏,下面是我们判断是否为模拟器环境的代码:// Swift 4.2 以前
#if (os(iOS) || os(watchOS) || os(tvOS) &&
(cpu(i396) || cpu(x86_64))
...
#endif
// Swift 4.2
#if hasTargetEnviroment(simulator)
...
#endif
废除 ImplicityUnwrappedOptional 类型
ImplicityUnwrappedOptional 又被称为强制解包可选类型,它其实是一个非必要的工具,我们使用它最主要的目的是,减少显式的解包,例如说 UIViewController 的生命周期里, view 在 init 的时候是一个空值,但是只要 viewDidLoad 之后就会一直存在,如果我们每次都使用都需要手动显式强制解包 view! 就会很繁琐,使用了 IUO 就可以节省这一部分解包代码。
所以 ImplicityUnwrappedOptional 是与 Objective-C 的 API 交互时很有用的一个工具,所有未被标记上 nullability 的变量都会被作为 IUO 类型暴露给 Swift,它的出现同时也是为了暂时填补 Swift 里语言的未定义部分,去处理那些固定模式的代码。随着语言的发展,我们应该明确 IUO 的作用,并且用好的方式去取代它。
SE-0054 提案就是为此而提出的,这个提案实际上在 Swift 3 里就实现了一部分了,在 Swift 4.2 里继续完善并且完整得实现了出来。
以往我们标记 IUO 的时候,都是通过类型的形式去实现,在 Swift 4.2 之后,IUO 不再是一个类型,而是一个标记,编译器会通过给变量标记上 @_autounwrapped 去实现,所有被标记为 IUO 的变量都由编译器在编译时进行隐式强制解包:let x: Int! = 0 // x 被标记为 IUO,类型其实还是 Optional<Int>
let y = x + 1 // 实际上编译时,编译器会转化为 x! + 1 去进行编译
这就更加符合我们的原本的目的,因为我们需要标记的是变量的 nullability,而通过类型去标记的话实际上我们是在给一个值标记上 IUO,而并非是变量。
当然,这样的改变也会给之前的代码带来影响,因为我们标记的对象针对的是变量,而并非类型,所以以往作为类型存在的 IUO 就会变成非法的声明:let a: [Int!] = [] // 编译不通过
内存独占访问权
同一时间内,代码对于某一段内存空间的访问是具有独占性,听起来很难懂是吧,举个例子你就明白了,在遍历数组的同时对数组进行修改:var a = [1, 2, 3]
for number in a {
a.append(number) // 产生未定义的行为
}
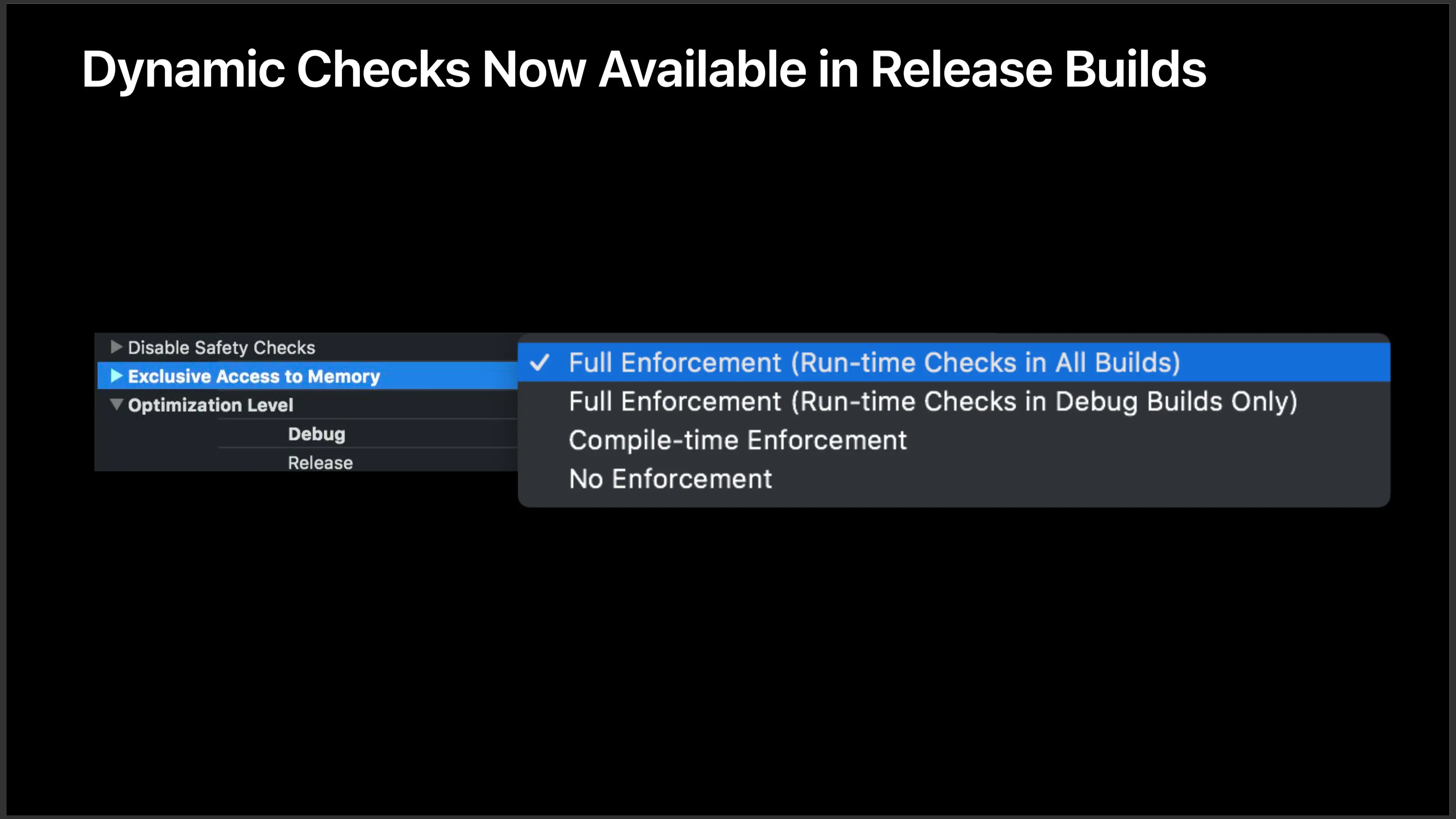
Swift 通过内存独占访问权的模型,可以在编译时检测出这种错误,在 Swift 4.2 里得到加强,可以检测出更多非法内存访问的情况,并且提供了运行时的检查,在未来,内存独占访问权的检查会像数组越界一样默认开启:
推荐资源
推荐查看Ole Begemann 大神的出品的 What’s new in Swift 4.2,带着大家用 Playground 亲身体会一下 Swift 里新的语法功能。
结语
Swift 5 是一个很重要的里程碑,ABI 的稳定意味着这一份设计需要支撑后面好几个大版本的功能需求,延期我觉得不算是一件坏事。待 ABI 尘埃落定之后,Swift 的语法功能肯定还会有一波爆发,async/await,原生的正则表达式…,都让我更加期待 2019 年的 Swift 5。